

Die Quantifizierung von Einzelrisiken mittels statistischer Methoden ist gängige Praxis im modernen Risikomanagement. Grundprinzipien der stochastischen Modellierung sowie deren Hilfsmittel (Extremwerttheorie, Risikomaße, Bayessche Statistik etc.) werden in der heutigen Berufspraxis von einem Risikomanager vorausgesetzt und in den entsprechenden Studiengängen gelehrt. Deutlich dünner wird die Luft wenn es um Risikoaggregation, bzw. die Modellierung von abhängigen stochastischen Größen, geht. Dabei sind es gerade gekoppelte stochastische Systeme, die uns vor besondere und häufig unterschätzte Risiken, und damit zentrale Herausforderungen in der Modellierung, stellen.
Offensichtliche Anwendungen, bei welchen Abhängigkeiten eine zentrale Rolle spielen, sind Kredit- und Aktienportfolios. Abhängigkeiten können aber auch subtiler Auftreten, ein aktuelles Beispiel sind CVA- und DVA-Adjustierungen für Derivate auf Grund von Kontrahentenrisiken; zu deren Quantifizierung explizit die Abhängigkeiten zwischen den Ausfallzeiten der Kontrahenten einerseits sowie dem Basisinstrument andererseits berücksichtigt werden müssen. Im Folgenden werden wir herausarbeiten, warum das Modellieren von multivariaten stochastischen Systemen deutlich schwerer ist als das Modellieren der eindimensionalen Risiken. Dabei werden wir auf strukturelle Probleme treffen, für die es nachweislich keine vollständige Lösung gibt, aber auch auf Probleme die von akademischer Seite aus als gelöst gelten, deren Lösung aber den Weg in die Praxis des Risikomanagements noch nicht gefunden hat.
Hintergrund: Copulas und der Satz von Sklar
Als Ausgangssituation stellen wir uns d Risiken vor, die jeweils als Zufallsvariable modelliert werden. Nehmen wir an, wir kennen für jedes Risiko die univariate Verteilungsfunktion und bezeichnen diese mit ![]() . Dieses Wissen allein reicht uns aber keinesfalls aus, um die gemeinsame Verteilungsfunktion zu bestimmen, da uns noch alle Informationen um die Abhängigkeit zwischen den Einzelgrößen fehlen. Wichtige Struktur liefert hierfür der Satz von Sklar. Dieser besagt, dass jede multivariate Verteilungsfunktion F in eine Copula C (eine Funktion, die selbst eine Verteilungsfunktion auf dem d-dimensionalen Einheitskubus mit uniformen Rändern ist) sowie die Randverteilungen
. Dieses Wissen allein reicht uns aber keinesfalls aus, um die gemeinsame Verteilungsfunktion zu bestimmen, da uns noch alle Informationen um die Abhängigkeit zwischen den Einzelgrößen fehlen. Wichtige Struktur liefert hierfür der Satz von Sklar. Dieser besagt, dass jede multivariate Verteilungsfunktion F in eine Copula C (eine Funktion, die selbst eine Verteilungsfunktion auf dem d-dimensionalen Einheitskubus mit uniformen Rändern ist) sowie die Randverteilungen ![]() aufgespalten werden kann. Die Randverteilungen werden dabei als Argumente in die Copula eingesetzt und man erhält so die gemeinsame Verteilung, das heißt
aufgespalten werden kann. Die Randverteilungen werden dabei als Argumente in die Copula eingesetzt und man erhält so die gemeinsame Verteilung, das heißt ![]() . Dies ist in vielen Situationen sehr angenehm, da es die oft sehr komplizierte Untersuchung der gemeinsamen Verteilungsfunktion separiert in eine Untersuchung der Randverteilungen einerseits und der Copula andererseits; in letzterer sind alle Informationen über die Abhängigkeit kodiert. Umgekehrt lässt sich aus beliebigen Randverteilungen und einer beliebigen Copula stets eine (mathematisch korrekte) multivariate Verteilungsfunktion konstruieren. Dieser Zusammenhang ist sehr beliebt in der Modellbildung und daher weit verbreitet, da er ein einfaches Bauprinzip zur Verknüpfung von Einzelrisiken darstellt. Auch lässt sich mittels dieses Bauprinzips leicht eine multivariate Verteilung simulieren. Dazu muss lediglich eine Stichprobe gemäß der Copula simuliert werden und diese dann mit Hilfe der univariaten Quantilsfunktionen umtransformiert werden. Leider weniger bekannt ist die Tatsache, dass wenn die Copula unpassend zum entsprechenden Problem (und den typischerweise vorab spezifizierten Randverteilungen) ausgesucht wird, zwar eine mathematisch korrekte gemeinsame Verteilung spezifiziert wird, diese aber keinesfalls ökonomisch sinnvoll oder problemadäquat sein muss. Oft werden schlichtweg die bekanntesten Copulas (Gauß-Copula, Archimedische Copulas, …) herangezogen, ohne deren Eigenschaften und Auswirkungen für das aktuelle Problem genau zu hinterfragen.
. Dies ist in vielen Situationen sehr angenehm, da es die oft sehr komplizierte Untersuchung der gemeinsamen Verteilungsfunktion separiert in eine Untersuchung der Randverteilungen einerseits und der Copula andererseits; in letzterer sind alle Informationen über die Abhängigkeit kodiert. Umgekehrt lässt sich aus beliebigen Randverteilungen und einer beliebigen Copula stets eine (mathematisch korrekte) multivariate Verteilungsfunktion konstruieren. Dieser Zusammenhang ist sehr beliebt in der Modellbildung und daher weit verbreitet, da er ein einfaches Bauprinzip zur Verknüpfung von Einzelrisiken darstellt. Auch lässt sich mittels dieses Bauprinzips leicht eine multivariate Verteilung simulieren. Dazu muss lediglich eine Stichprobe gemäß der Copula simuliert werden und diese dann mit Hilfe der univariaten Quantilsfunktionen umtransformiert werden. Leider weniger bekannt ist die Tatsache, dass wenn die Copula unpassend zum entsprechenden Problem (und den typischerweise vorab spezifizierten Randverteilungen) ausgesucht wird, zwar eine mathematisch korrekte gemeinsame Verteilung spezifiziert wird, diese aber keinesfalls ökonomisch sinnvoll oder problemadäquat sein muss. Oft werden schlichtweg die bekanntesten Copulas (Gauß-Copula, Archimedische Copulas, …) herangezogen, ohne deren Eigenschaften und Auswirkungen für das aktuelle Problem genau zu hinterfragen.
Fazit: Jede gemeinsame Verteilungsfunktion kann in ihre Randverteilungen und ihre Abhängigkeitsstruktur aufgespalten werden. Letztere wird durch eine Copula vollständig beschrieben.
Unterschiedliche Ränder + symmetrische Copula = Vorsicht
Ein einfaches Beispiel, welches gut die Wirkungsweise des Satzes von Sklar illustriert, entsteht schon bei der gemeinsamen Modellierung von nur zwei Ausfallzeiten. Stellen wir uns vor, wir modellieren für eine Simulationsstudie die Ausfallzeiten zweier Firmen mit Hilfe zweier Exponentialverteilungen ![]() und
und ![]() . Das bedeutet, die erste Firma fällt im Mittel nach 1/0.01 = 100 Jahren aus, die zweite Firma nach 1/0.02 = 50 Jahren. Wenn wir diese Ausfallzeiten unabhängig voneinander simulieren, dann wird sicherlich häufig (aber nicht immer) die zweite Firma als erste ausfallen. Nun sollen diese Ausfallzeiten aber abhängig modelliert werden. Eine Gumbel-Copula soll dabei helfen, die Abhängigkeitsstruktur zu beschreiben. Die Gumbel Copula stammt aus der Klasse der Archimedischen Copulas und besitzt als Grenzfälle die Fähigkeit Unabhängigkeit und volle Abhängigkeit zu modellieren. Die Gumbel Copula ist dabei symmetrisch im Sinne von C(u,v) = C(v,u). Intuitiv würde man nun vermuten, dass wenn die Abhängigkeit zunimmt, die Ausfallzeiten häufiger (d.h. mit größerer Wahrscheinlichkeit) nahe beisammen liegen. Dies ist aber gerade nicht der Fall. Im Gegenteil, man erhält sogar eine gänzlich unnatürliche Anordnung: Bei voller Abhängigkeit wird stets die zweite Firma als erstes ausfallen, d.h.
. Das bedeutet, die erste Firma fällt im Mittel nach 1/0.01 = 100 Jahren aus, die zweite Firma nach 1/0.02 = 50 Jahren. Wenn wir diese Ausfallzeiten unabhängig voneinander simulieren, dann wird sicherlich häufig (aber nicht immer) die zweite Firma als erste ausfallen. Nun sollen diese Ausfallzeiten aber abhängig modelliert werden. Eine Gumbel-Copula soll dabei helfen, die Abhängigkeitsstruktur zu beschreiben. Die Gumbel Copula stammt aus der Klasse der Archimedischen Copulas und besitzt als Grenzfälle die Fähigkeit Unabhängigkeit und volle Abhängigkeit zu modellieren. Die Gumbel Copula ist dabei symmetrisch im Sinne von C(u,v) = C(v,u). Intuitiv würde man nun vermuten, dass wenn die Abhängigkeit zunimmt, die Ausfallzeiten häufiger (d.h. mit größerer Wahrscheinlichkeit) nahe beisammen liegen. Dies ist aber gerade nicht der Fall. Im Gegenteil, man erhält sogar eine gänzlich unnatürliche Anordnung: Bei voller Abhängigkeit wird stets die zweite Firma als erstes ausfallen, d.h. ![]() in jedem Szenario. Wie lässt sich dies erklären? Die volle Abhängigkeit wird durch die Copula M(u,v) = min (u,v) beschrieben. Simuliert man diese, so sind beide Komponenten exakt identisch, man erhält also einen Vektor (U,U) mit U~Uniform(0,1). Wendet man nun die Quantilsfunktionen der Exponentialverteilung auf diesen Vektor an, so erhält man
in jedem Szenario. Wie lässt sich dies erklären? Die volle Abhängigkeit wird durch die Copula M(u,v) = min (u,v) beschrieben. Simuliert man diese, so sind beide Komponenten exakt identisch, man erhält also einen Vektor (U,U) mit U~Uniform(0,1). Wendet man nun die Quantilsfunktionen der Exponentialverteilung auf diesen Vektor an, so erhält man ![]() . Damit ist klar, dass die erste Firma zwingend nach der zweiten Firma ausfällt und damit unsere Intuition versagt. Es gilt sogar, dass
. Damit ist klar, dass die erste Firma zwingend nach der zweiten Firma ausfällt und damit unsere Intuition versagt. Es gilt sogar, dass ![]() , d.h. die erste Firma überlebt immer exakt doppelt so lange wie die zweite Firma; was sicherlich kein sonderlich realistisches Modell darstellt. Der mathematische Hintergrund dieses Phänomens ist die Tatsache, dass die Randverteilungen der beiden Firmen unterschiedlich sind (inhomogen), während die Copula selbst symmetrisch (austauschbar) ist. Dies führt häufig, so auch hier, zu ungewollten Effekten. Identisch gilt diese Warnung übrigens auch für die populäre Gauß-Copula, da diese (im zweidimensionalen Fall) ebenfalls symmetrisch ist.
, d.h. die erste Firma überlebt immer exakt doppelt so lange wie die zweite Firma; was sicherlich kein sonderlich realistisches Modell darstellt. Der mathematische Hintergrund dieses Phänomens ist die Tatsache, dass die Randverteilungen der beiden Firmen unterschiedlich sind (inhomogen), während die Copula selbst symmetrisch (austauschbar) ist. Dies führt häufig, so auch hier, zu ungewollten Effekten. Identisch gilt diese Warnung übrigens auch für die populäre Gauß-Copula, da diese (im zweidimensionalen Fall) ebenfalls symmetrisch ist.
Fazit: Der Satz von Sklar lehrt uns, dass beliebige Randverteilungen mit beliebigen Copulas zu einer gemeinsamen Verteilung verknüpft werden können. Nicht aber ist sichergestellt, dass diese Verteilungsfunktion für jede Problemstellung adäquat ist. Es ist also unumgänglich, die stochastischen Eigenschaften von Copulas besser zu verstehen, um nicht ungewollten Phänomenen ausgesetzt zu sein.
Stochastische Eigenschaften von Copulas
Für univariate Verteilungen sind viele strukturelle Eigenschaften bekannt und meist leicht zu interpretieren. So kann sich sicherlich jeder vorstellen, dass bei einer "heavy-tailed" Verteilung extreme Beobachtungen häufiger vorkommen als bei einer "light-tailed" Verteilung. Ähnliche strukturelle Eigenschaften identifiziert man bei Copulas. Diesen Eigenschaften sollte man sich unbedingt bewusst sein, da sie essentiell das multivariate Verhalten des zu spezifizierenden Zufallsvektors beeinflussen. Wir zählen in der Folge einige auf:
- Untere (bzw. obere) "Tail-Dependence": Darunter versteht man mathematisch gesprochen den Grenzwert gegen Null (bzw. Eins) der bedingten Wahrscheinlichkeit für eine sehr kleine (bzw. sehr große) Beobachtung in einer Komponente der Copula, gegeben, dass die andere Komponente sehr klein (bzw. sehr groß) ist. Intuitiv gesprochen lässt sich am Koeffizienten der Tail-Dependence einer Copula ablesen, ob diese prinzipiell in der Lage ist, die Abhängigkeit extremer Beobachtungen für besonders kleine (bzw. große) Beobachtungen zu beschreiben. Diese Eigenschaft spielt insbesondere dann eine zentrale Rolle, wenn seltene Ereignisse von großer Bedeutung sind. Wieder bietet sich das Beispiel von Kreditausfällen an. Hier sind wir an der korrekten Quantifizierung des Risikos gemeinsamer Ausfälle (also seltener Ereignisse) interessiert. Für solch eine Anwendung sollte eine Copula mit positiver Tail-Dependence eingesetzt werden.
- Symmetrie: Eine Copula ist symmetrisch (austauschbar), wenn sie invariant unter Permutationen ihrer Argumente ist, im bivariaten also
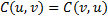 gilt. Anschaulich gesprochen kann man sich darunter eine Abhängigkeitsstruktur ohne Gruppierungen vorstellen, bei der in gewissem Sinne alle Komponenten gleichberechtigt sind. Häufig – wie Eingangs skizziert – führt diese Eigenschaft zu erratischen Situationen wenn die Randverteilungen nicht auch austauschbar, also identisch, sind.
gilt. Anschaulich gesprochen kann man sich darunter eine Abhängigkeitsstruktur ohne Gruppierungen vorstellen, bei der in gewissem Sinne alle Komponenten gleichberechtigt sind. Häufig – wie Eingangs skizziert – führt diese Eigenschaft zu erratischen Situationen wenn die Randverteilungen nicht auch austauschbar, also identisch, sind. - Singuläre Komponente: Eine d-dimensionale Copula besitzt eine singuläre Komponente, wenn positive Wahrscheinlichkeitsmasse auf einer unter-dimensionalen Teilmenge verteilt ist. Bildlich kann man sich dies leicht in Dimension 2 vorstellen, es ist dann beispielsweise positive Masse auf der ersten Winkelhalbierenden allokiert. Anschaulich bedeutet dies wiederum, dass beispielsweise Firmenausfälle (bei identischen Rändern, sonst läuft man in das oben skizzierte Paradoxon) mit positiver Wahrscheinlichkeit exakt zum gleichen Zeitpunkt auftreten. Je nach Anwendung kann dies eine gewünschte aber auch unrealistische statistische Eigenschaft sein.
Fazit: Es sollte a priori zur Modellkonstruktion eine Liste aller als relevant erachteten stochastischen Eigenschaften der Abhängigkeitsstruktur erstellt werden. Basierend auf diesen Anforderungen erfolgt dann die Wahl einer geeigneten Copula.
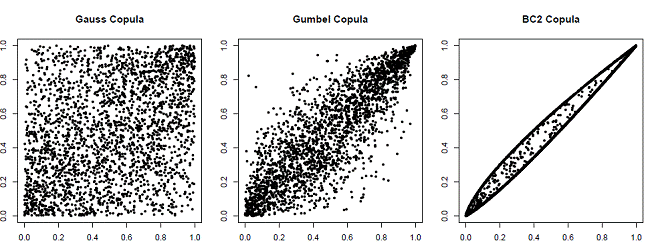
Abb. 01: Gauss Copula, Gumbel Copula und BC2 Copula
Anhand der drei Copulas (Gauss, Gumbel und BC2) können die oben skizzierten stochastischen Eigenschaften gut visualisiert werden (vgl. Abb. 01). Es werden jeweils 2.500 Zufallsvektoren entsprechend der Copulas simuliert und im Koordinatensystem als Punktewolke (Scatterplot) eingetragen. Vergleicht man Gumbel- mit Gauss Copula, so erkennt man bei letzterer die Häufung von Punkten oben rechts. Dem entspricht die positive obere Tail Dependence. Beide Copulas sind aber symmetrisch entlang der ersten Winkelhalbierenden, wohingegen die BC2 Copula eine (leichte) Asymmetrie aufweist. Auch lässt sich leicht die singuläre Komponente der BC2 Copula erkennen, hier hat man positive Wahrscheinlichkeit auf zwei Pfaden, welche die Punkte (0,0) mit (1,1) verbinden, allokiert.
Die Welt ist "nicht Normal"
Die einzige mehrdimensionale Verteilungsklasse, welche standardmäßig im Mathematikstudium gelehrt wird, ist die multivariate Normalverteilung. Deren Popularität hat mehrere Gründe:
- Die multivariate Normalverteilung hat eine natürliche Motivation in der Statistik durch den (mehrdimensionalen) zentralen Grenzwertsatz. Zum Beispiel sind Schätzfehler häufig asymptotisch normalverteilt. Folglich kann man argumentieren, dass es Sinn macht eine "Ungenauigkeit" normalverteilt zu modellieren, da dies in vielen Fällen zumindest asymptotisch zutrifft.
- Sowohl die Dichtefunktion als auch die charakteristische Funktion der multivariaten Normalverteilung sind in geschlossener Form verfügbar und außerordentlich angenehm um damit zu Rechnen. Auch deswegen basieren viele klassische, statistische Tests auf der Theorie der multivariaten Normalverteilung.
- Die multivariate Normalverteilung ist vollständig bestimmt durch einen Mittelwertvektor und eine Kovarianzmatrix. Dies verhilft zu einem schnellen Verständniszugang, da man sich lediglich die Abhängigkeiten (= Korrelationen) zwischen den einzelnen Paaren vorstellen muss.
- Linearkombinationen von Zufallsvariablen, welche multivariat normalverteilt sind, sind wiederum normalverteilt. Dieser Konsistenzbedingung liegt ein tiefer innerer Zusammenhang zur linearen Algebra zugrunde, welcher zum Beispiel die Konstruktion von Faktormodellen ermöglicht. Letztere sind sehr intuitiv und daher in praktischen Anwendungen sehr beliebt.
Diese Popularität der multivariaten Normalverteilung führte aber auch dazu, dass sie in vielen Anwendungen außerhalb der reinen Statistik oft ungeprüft herangezogen wurde, wenn ein Abhängigkeitsmodell von Nöten war. Leider muss man konstatieren, dass für manche Anwendungen – insbesondere in der Kreditrisikomodellierung – die multivariate Normalverteilung (bzw. die davon abgeleitete Gauss-Copula) alles andere als natürlich ist. Denn:
- Möchte man abhängige Ausfallzeiten konstruieren, so müssen die Randverteilungen positiv sein. Die Normalverteilung hat aber keine positiven Ränder. Daher wird diese häufig zunächst auf ihre Copula heruntergebrochen, dann werden mit Hilfe des Satzes von Sklar in einem zweiten Schritt positive Randverteilungen, zum Beispiel exponentielle Ränder, eingesetzt. Dieses unnatürliche Vorgehen kann man durchaus als "algebraischen Missbrauch" bezeichnen. Wäre es nicht etwa natürlicher, direkt mit einer multivariaten Exponentialverteilung zu arbeiten? Solche Konzepte existieren!
- Anschaulich basiert das Konzept der Normalverteilung auf der Idee eines Mittelwertes und einer Streuung um diesen Mittelwert, welche durch die Kovarianzmatrix festgelegt wird. Aber die Idee von Ausreißern, das heißt Werten fernab des Mittelwertes mit kleiner Wahrscheinlichkeit, taucht in diesem Konzept nicht hinreichend auf. Übertragen auf Anwendungen bedeutet dies, dass katastrophale Ereignisse (mit multiplen Schäden) so gut wie nicht auftreten können und somit deren Eintrittswahrscheinlichkeit unterschätzt wird. Diese Schwäche der Normalverteilung wurde in den letzten Jahren, insbesondere während der Finanzkrise, in unzähligen wissenschaftlichen Arbeiten offengelegt.
- Die Normalverteilung ist light-tailed. Eine der populärsten Anwendungen der Finanzmathematik überhaupt, nämlich die klassische Portfoliooptimierung à la Markowitz, basiert auf der Tatsache, dass die Varianzen und Kovarianzen existieren. Eine sich daraus ableitende Grundregel, welche jeder Student verinnerlicht hat, lautet, dass Diversifizierung das Risiko verringert. Allerdings muss genau diese Regel nicht mehr gelten, wenn man den Normalverteilungskosmos verlässt. Dies lässt sich im übertragenen Sinne an folgendem Beispiel veranschaulichen: Angenommen Sie müssen einen Drink mixen aus zwei Flüssigkeiten, wobei sie wissen, dass eine der beiden Flüssigkeiten ein tödliches Gift ist (Sie können die Flüssigkeiten aber nicht auseinander halten). Würden Sie sich für eine Mischung der beiden Flüssigkeiten entscheiden, oder lieber Ihr Glas komplett mit nur einer der beiden Flüssigkeiten auffüllen? Da die erste Option zum sicheren Tod führt, würde jeder rationale Mensch die zweite Option wählen; also ist Diversifikation in diesem Falle tödlich! Mathematisch symbolisieren die Flüssigkeiten Risiken mit unendlicher Varianz (beispielsweise geeignet parametrisierte Pareto Verteilungen), welche in der Normalverteilungswelt ausgeschlossen sind.
Fazit: Für viele Anwendungen ist die Normalverteilung nicht geeignet. Speziell bei Extremen Risiken sollten andere Verteilungsklassen bevorzugt werden.
Schätzen der Parameter
Nachdem ein parametrisches Modell für die Ränder und die Copula aufgestellt ist, wird man sich zwingend mit der Frage der Parameterwahl auseinandersetzen. Hierzu nutzt man konzeptionell ähnliche Verfahren wie in der eindimensionalen Statistik, allerdings treten wieder gewisse Fallstricke auf.
- Gerne nutzt man, analog zur univariaten Statistik, Maximum-Likelihood Verfahren um die Parameter einer Copula zu schätzen. Dies erfordert die Verfügbarkeit einer Dichte, was speziell bei Copulas mit Singulärer Komponente oft nicht gegeben ist. Ist die Copula allerdings hinreichend glatt, so erhält man deren Dichte durch sequenzielles partielles Ableiten nach allen Argumenten. In kleinen Dimensionen ist dies in der Regel unkritisch, allerdings werden diese Ableitungen für hohe Dimensionen in vielen Fällen zur echten Herausforderung. Selbst wenn eine theoretische Lösung für die d-fache Ableitung bekannt ist, muss diese nämlich noch nicht numerisch stabil zu implementieren sein. In manchen Anwendungen stehen einem die Parameter der Randverteilungen nicht zur Verfügung. Dann wird sehr gerne eine sequenzielle Methode benutzt, welche IFM genannt wird. Es werden bei dieser Methode zunächst die Parameter der Randverteilungen mittels eines Maximum-Likelihood Ansatzes geschätzt. Diese werden dann genutzt um die Stichproben auf uniforme Ränder zu transformieren. In einem zweiten Schritt werden dann die Parameter der Copula mittels Maximum-Likelihood geschätzt. Unter gewissen Annahmen lässt sich für dieses Verfahren zeigen, dass die so erhaltenen Schätzer (geeignet normiert) normalverteilt um die echten Parameter sind.
- Ein anderes Vorgehen bietet sich bei niederdimensionalen Copulas an, es kann analog zum eindimensionalen als Momentenmethode interpretiert werden. Hierfür werden gewisse Abhängigkeitsmaße berechnet (beispielsweise Kendall’s Tau, Spearman’s Rho) und diese in einen funktionalen Zusammenhang zu den Parametern der Copula gebracht. Dann werden diese Parameter so gewählt, dass die empirischen Abhängigkeitsmaße mit den theoretischen überein stimmen.
Prinzipiell haben alle Verfahren der Parameterschätzung die Gemeinsamkeit, dass mehr Stichproben benötigt werden, als man aus der eindimensionalen Statistik gewohnt ist. Dieses Statement ist so getroffen natürlich mathematisch nicht präzise, ist aber als Faustformel sicherlich zutreffend. Andere Fallstricke beobachtet man wenn die Dimension ansteigt. Häufig hat man dann mit einer schnell ansteigenden Anzahl an Parametern zu kämpfen, was deren Schätzung wiederum erschwert. Auch wird oft vergessen, dass mit bivariaten Abhängigkeitsmaßen eben nur Informationen über bivariate Abhängigkeiten erzielt werden können und diese noch nicht die gemeinsame Verteilung vollständig spezifizieren müssen.
Fazit: Die Schätzer der Parameter der Abhängigkeitsstruktur weisen typischerweise eine höhere Varianz auf als die Schätzer für die Parameter der Randverteilungen. Daher sollten die geschätzten Parameter, so nur kleine Datenmengen zur Verfügung stehen, auch sehr kritisch gesehen werden. Eine Möglichkeit mit diesem Problem umzugehen ist es, die geschätzten Parameter als Basis für darauf konstruierte Stressszenarien zu nutzen, um gegen mögliche Schätzfehler gewappnet zu sein.
Der Fluch der Dimension
Das Arbeiten mit Copulas wird häufig in höheren Dimensionen zur echten Herausforderung. Dies wird in vielen Büchern und Artikeln umgangen, indem schlichtweg nur der zweidimensionale Fall betrachtet wird und (explizit oder implizit) suggeriert wird, dass Erweiterungen zu höheren Dimensionen leicht möglich sind. Diese Behauptung trifft aber nur selten zu, wie die nachstehenden Fälle illustrieren.
- Schon das Auswerten von elementaren Wahrscheinlichkeiten wird numerisch kompliziert. Die gemeinsame Verteilungsfunktion eines Zufallsvektors gibt an, mit welcher Wahrscheinlichkeit die Einzelrisiken kleiner oder gleich gewisser Werte sind. Will man nun die Wahrscheinlichkeit berechnen, dass diese Risiken innerhalb eines gewissen Rechteckes liegen (sicherlich keine unübliche Frage), müssen in Dimension d schon
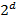 Summanden ausgewertet und aufsummiert werden. Der (numerische) Aufwand steigt also zwingend exponentiell in der Dimension an, wird somit sehr schnell unbeherrschbar.
Summanden ausgewertet und aufsummiert werden. Der (numerische) Aufwand steigt also zwingend exponentiell in der Dimension an, wird somit sehr schnell unbeherrschbar. - Die Anzahl der Parameter explodiert oder implodiert: Die Anzahl der Paare eines d- elementigen Zufallsvektors ist d (d-1)/2. Die Anzahl der nicht-leeren Teilmengen bereits
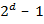 . Viele multivariate Verteilungen und Copulas haben größenordnungsmäßig diese Anzahl an Parametern. In hohen Dimensionen ist dies schlicht nicht mehr zu beherrschen (im Sinne von einfach zu verwalten, zu schätzen, zu simulieren etc.). Daher müssen vereinfachte Unterfamilien identifiziert werden, die das praktische Problem, was es konkret zu modellieren gilt, mit einer kleineren Anzahl an Parametern zumindest approximativ beschreiben können. Aber auch der umgekehrte Fall kann auftreten: Die Parameterzahl ist unabhängig von der Dimension (beispielsweise für klassische Archimedische Copulas). Solche Verteilungen und Copulas werden für steigende Dimensionen wiederum zu unflexibel, um die vielseitigen Wechselwirkungen realistisch zu beschreiben. Eine mögliche Lösung für dieses Dilemma können im Fall der Archimedischen Copulas hierarchische Erweiterungen bieten. Oft helfen auch Transformationen von Copulas diese flexibler zu machen und mit mehr Parametern auszustatten.
. Viele multivariate Verteilungen und Copulas haben größenordnungsmäßig diese Anzahl an Parametern. In hohen Dimensionen ist dies schlicht nicht mehr zu beherrschen (im Sinne von einfach zu verwalten, zu schätzen, zu simulieren etc.). Daher müssen vereinfachte Unterfamilien identifiziert werden, die das praktische Problem, was es konkret zu modellieren gilt, mit einer kleineren Anzahl an Parametern zumindest approximativ beschreiben können. Aber auch der umgekehrte Fall kann auftreten: Die Parameterzahl ist unabhängig von der Dimension (beispielsweise für klassische Archimedische Copulas). Solche Verteilungen und Copulas werden für steigende Dimensionen wiederum zu unflexibel, um die vielseitigen Wechselwirkungen realistisch zu beschreiben. Eine mögliche Lösung für dieses Dilemma können im Fall der Archimedischen Copulas hierarchische Erweiterungen bieten. Oft helfen auch Transformationen von Copulas diese flexibler zu machen und mit mehr Parametern auszustatten. - Ein weiteres Problem ist die Unmöglichkeit der vollständigen Visualisierung von Stichproben der Dimensionen größer als 3. Als Analogon zum eindimensionalen Histogramm werden in der multivariaten Statistik gerne sogenannte Scatterplots (siehe Abb. 01) herangezogen. Hierin werden die Stichproben in einem Koordinatensystem eingetragen. Regionen, in welchen sich die Stichproben häufen, korrespondieren zu Regionen von hoher Wahrscheinlichkeitsmasse. Dieses Verfahren ermöglicht die sehr schnelle und anschauliche Visualisierung von 2- oder 3- dimensionalen Daten. Ein höher-dimensionales Koordinatensystem lässt sich aber nicht analog visualisieren; hierfür fehlt uns offensichtlich die Phantasie. Als (Not-)Lösung werden häufig Scatterplot-Matrizen herangezogen, die alle bivariaten Paare visualisieren. Dies ist sicherlich eine gute Methodik, solange nicht vergessen wird, dass die bivariaten Paare die gemeinsame Verteilung im Allgemeinen nicht vollständig festlegen.
- Aussagen, die in Dimension 2 gelten, sind oft falsch in größeren Dimensionen. Beispiele hierfür gibt es mannigfaltige. Ein sehr bekanntes ist die Charakterisierung von Archimedischen Generatoren (fallende Funktionen von
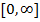 nach
nach 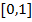 mit
mit 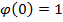 ) in Dimension 2 mittels Konvexität. Diese Charakterisierung hängt allerdings explizit von der Dimension ab und wird in höheren Dimensionen deutlich diffiziler.
) in Dimension 2 mittels Konvexität. Diese Charakterisierung hängt allerdings explizit von der Dimension ab und wird in höheren Dimensionen deutlich diffiziler. - Negative Abhängigkeiten für
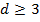 . Während man für die vollständige Abhängigkeit einer Copula in beliebiger Dimension eine sehr einfache Motivation hat (die Komponenten sind fast sicher identisch, also
. Während man für die vollständige Abhängigkeit einer Copula in beliebiger Dimension eine sehr einfache Motivation hat (die Komponenten sind fast sicher identisch, also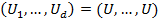 , die gemeinsame Copula ist
, die gemeinsame Copula ist 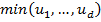 ) ist dies für negative Abhängigkeiten nicht der Fall. Starten wir bei Dimension 2. Hier ist negative Abhängigkeit noch einfach zu definieren, die erste Komponente sei dazu
) ist dies für negative Abhängigkeiten nicht der Fall. Starten wir bei Dimension 2. Hier ist negative Abhängigkeit noch einfach zu definieren, die erste Komponente sei dazu 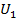 . Dann ist die größtmögliche negative Abhängigkeit gerade
. Dann ist die größtmögliche negative Abhängigkeit gerade 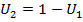 , die gemeinsame Copula ergibt sich zu
, die gemeinsame Copula ergibt sich zu 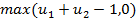 . In Dimension 3 (und darüber hinaus) ist es aber nicht mehr möglich
. In Dimension 3 (und darüber hinaus) ist es aber nicht mehr möglich 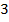 Komponenten in maximal unterschiedliche Richtungen anzuordnen, weil es anwendungsabhängig verschiedene sinnvolle Definitionen für die Verschiedenheit dreier Richtungen gibt. Algebraisch gesprochen könnten wir versuchen die Funktion
Komponenten in maximal unterschiedliche Richtungen anzuordnen, weil es anwendungsabhängig verschiedene sinnvolle Definitionen für die Verschiedenheit dreier Richtungen gibt. Algebraisch gesprochen könnten wir versuchen die Funktion 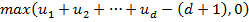 als natürliche Erweiterung der Copula der negativen Abhängigkeit zu betrachten. Diese Funktion, obgleich mathematisch relevant, ist selbst keine Copula mehr. Das heißt, es gibt keinen Zufallsvektor mit eben dieser Verteilungsfunktion.
als natürliche Erweiterung der Copula der negativen Abhängigkeit zu betrachten. Diese Funktion, obgleich mathematisch relevant, ist selbst keine Copula mehr. Das heißt, es gibt keinen Zufallsvektor mit eben dieser Verteilungsfunktion.
Fazit: In hohen Dimensionen muss stets ein Kompromiss gefunden werden, welcher die Struktur der Abhängigkeit zwar auf ein mathematisch handhabbares Maß vereinfacht, die zu modellierenden Phänomene aber nicht übersimplifiziert. Idealerweise findet sich eine möglichst einfache Parameterisierung, die für jedes als relevant erachtete stochastische Phänomen genau einen Parameter besitzt.
Abhängigkeitsmaße und deren korrekte Interpretation
Es gibt ein omnipräsentes Maß für Abhängigkeit, welches nicht nur in der angewandten Finanzmathematik, sondern auch in vielen anderen Anwendungsbereichen verwendet wird, nämlich die lineare Korrelation. Der (Pearson'sche) Korrelationskoeffizient ![]() zwischen zwei Zufallsvariablen X und Y mit endlichen Varianzen
zwischen zwei Zufallsvariablen X und Y mit endlichen Varianzen ![]() und
und ![]() , sowie Kovarianz
, sowie Kovarianz ![]() ist definiert über
ist definiert über ![]() . Die Korrelation kann interpretiert werden als eine Maßzahl für die Stärke der stochastischen Abhängigkeit zwischen X und Y. Sie nimmt stets Werte zwischen -1 und +1 an, wobei im Falle der Unabhängigkeit eine Korrelation von Null vorherrscht. Die Popularität der Korrelation als Maßzahl für die Stärke der stochastischen Abhängigkeit hat viele Gründe, wir nennen einige:
. Die Korrelation kann interpretiert werden als eine Maßzahl für die Stärke der stochastischen Abhängigkeit zwischen X und Y. Sie nimmt stets Werte zwischen -1 und +1 an, wobei im Falle der Unabhängigkeit eine Korrelation von Null vorherrscht. Die Popularität der Korrelation als Maßzahl für die Stärke der stochastischen Abhängigkeit hat viele Gründe, wir nennen einige:
- Es gibt einen inneren Zusammenhang zur Normalverteilung. Wir haben schon in einem vorigen Abschnitt gesehen, dass die multivariate Normalverteilung aus vielen Gründen die bekannteste und beliebteste mehrdimensionale Verteilungsklasse ist. Es gibt viele mathematische Indizien dafür, dass innerhalb dieser Verteilungsklasse die Korrelation tatsächlich das beste Maß für Abhängigkeit darstellt.
- Es gibt einen kanonischen und leicht verständlichen (sowie umzusetzenden) Schätzer für den Korrelationskoeffizienten, den "empirischen Korrelationskoeffizienten". Gegeben n unabhängige und gleichverteilte Stichproben
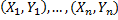 eines Merkmals
eines Merkmals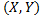 , ist dieser gegeben durch
, ist dieser gegeben durch 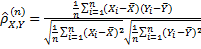 , wobei
, wobei 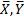 die Stichprobenmittelwerte der Komponenten bezeichnen. Dies ermöglicht es auf einfache Art und Weise ein Maß für die Abhängigkeit gegebener Daten zu berechnen.
die Stichprobenmittelwerte der Komponenten bezeichnen. Dies ermöglicht es auf einfache Art und Weise ein Maß für die Abhängigkeit gegebener Daten zu berechnen. - Die Intuition hinter dem Korrelationskoeffizienten ist sehr einfach und einleuchtend. Er misst die Stärke der (linearen) Abhängigkeit zwischen zwei zufälligen Größen X und Y auf einer Skala von -1 bis +1, wobei negative Werte anschaulich bedeuten, dass ein Ausschlag von X nach oben mit hoher Wahrscheinlichkeit einen Ausschlag von Y nach unten bewirkt, und umgekehrt. Positive Werte werden anschaulich interpretiert dadurch, dass beide Größen mit hoher Wahrscheinlichkeit in dieselbe Richtung ausschlagen. Dieser einfache Verständniszugang führte dazu, dass die Korrelation den Kosmos des reinen mathematischen Begriffes verlassen hat und auch als Vokabel in unseren täglichen Sprachgebrauch integriert wurde.
Allerdings bietet die Korrelation auch einige Nachteile, welche man sich vor Augen führen sollte.
- Außerhalb der Normalverteilungswelt muss die Korrelation nicht mehr das natürlichste Maß für die Abhängigkeitsstärke zwischen Zufallsvariablen sein. Insbesondere kann es sein, dass bei einem Zufallsvektor der Dimension größer als zwei die Kenntnis aller paarweisen Korrelationen gar nicht ausreicht, um die gemeinsame Wahrscheinlichkeitsverteilung des Zufallsvektors festzulegen. Zum Beispiel gibt es dreidimensionale Zufallsvektoren, deren paarweise Korrelationen allesamt Null sind, aber die drei Zufallsvariablen sind trotzdem nicht stochastisch unabhängig sind.
- Der Pearson'sche Korrelationskoeffizient misst nur die "lineare Abhängigkeit" zwischen zwei Zufallsvariablen. Es kann durchaus sein, dass zwei Zufallsvariablen stark abhängig sind (in einem anderen, intuitiven Sinne), aber deren Korrelation Null ist. Ein einfaches Beispiel ist die Korrelation zwischen X und X² für eine standardnormalverteilte Zufallsgröße X. Jeder würde intuitiv zustimmen, dass diese beiden Größen stark abhängig sind, jedoch ist ihre Korrelation tatsächlich Null. Solche Probleme können behoben werden, indem man anstelle des Korrelationskoeffizienten ein sogenanntes Konkordanzmaß betrachtet. Die bekanntesten Konkordanzmaße sind Kendall's Tau und Spearman's Rho. Diese Maße können die Abhängigkeit genauer erfassen und sind nicht nur auf den linearen Anteil der Abhängigkeit eingeschränkt. Außerdem gibt es für diese Maße, genauso wie für die Korrelation, empirische Pendants, welche es ermöglichen aus gegebenen Daten die jeweiligen theoretischen Größen einfach und präzise zu schätzen.
- Die einfache Intuition der Korrelation basiert maßgeblich auf der Tatsache, dass sie die Realität sehr stark vereinfacht. Zunächst ist eine Korrelation stets eine Maßzahl für die Stärke der Abhängigkeit zwischen zwei Zufallsgrößen. In einem hochdimensionalen (und mitunter hochkomplexen) System mit mehr als zwei Zufallsgrößen kann es sein, dass fundamentale kausale Zusammenhänge innerhalb des Gesamtsystems übersehen werden, wenn man nur alle paarweisen Korrelationen betrachtet. Man stelle sich zum Beispiel eine Situation vor in dem (nur) das gemeinsame Auftreten zweier Ereignisse ein drittes Ereignis auslöst. Dann besteht hier sicherlich eine starke Abhängigkeit zwischen allen drei Ereignissen, aber eventuell eine schwache Abhängigkeit zwischen je zwei Ereignissen. Außerdem ist es grundsätzlich gefährlich etwas so komplexes wie eine Abhängigkeitsstruktur zwischen zwei zufälligen Größen auf eine einzige Zahl herunter zu brechen. Der Informationsverlust, welcher mit dieser Projektion der Abhängigkeit auf die Korrelation einhergeht, kann enorm groß sein, eben vor allem außerhalb der Normalverteilungswelt.
Fazit: Gerade das reduzierte Denken in Korrelationen als alleiniges Maß für die Abhängigkeit birgt große Gefahren, da die Korrelation nur ein Maß für die lineare Abhängigkeit darstellt. Man sollte sich stets darüber im Klaren sein, dass das Reduzieren der Information über die Abhängigkeit mittels eines Abhängigkeitsmaßes einen massiven Verlust an Informationen impliziert.
Fazit sowie weiterführende Literaturhinweise
Copulas können aus verschiedenen Blickwinkeln untersucht werden, üblich sind analytische, statistische oder stochastische Verfahren (vgl. Infobox). Einen sehr analytischen Zugang bietet das Lehrbuch [Nelson 2006], hierin wird sehr ausführlich das Basiswissen zu Copulas hergeleitet und anhand vieler Übungsaufgaben vertieft. Das Buch fokussiert meist auf den bivariaten Fall, was zwar den Einstieg erleichtert, aber weiterführende Literatur notwendig macht. Einen statistischen Zugang zu Copulas liefert [Joe 1997]. Dieses Buch kann ohne Zweifel als Kompendium bezeichnet werden und sollte in keiner gutsortierten Bücherei fehlen; als erstes Lehrbuch ist es aber eventuell zu ambitioniert. Einen stochastischen Ansatz verfolgen [Mai/Scherer 2012]. Dieser Ansatz ist insbesondere gut geeignet für Simulationsanwendungen. So werden in diesem Buch auch Simulationsalgorithmen und viele Beispiele zu allen gängigen Copulafamilien geliefert.
Quellenverzeichnis sowie weiterführende Literaturhinweise:
Joe, H. (1997): Multivariate Models and Dependence Concepts, Chapman and Hall/CRC.
Mai, J.-F./Scherer, M. (2012): Simulating Copulas: Stochastic Models, Sampling Algorithms, and Applications, Imperial College Press.
Nelsen, R. (2006): An Introduction to Copulas, Springer, 2te Edition.
Infobox: Hätten Sie es gewusst?
|
Über die Autoren:
Dr. Jan-Frederik Mai arbeitet als Quantitative Analyst beim Münchner Assetmanager Assenagon Credit Management GmbH.
Prof. Dr. Matthias Scherer ist Professor für Finanzmathematik an der Technischen Universität München.
Beide sind Autoren des Buches Simulating Copulas: Stochastic Models, Sampling Algorithms, and Applications, erschienen 2012 bei Imperial College Press.
[Bildquelle: © djama - Fotolia.com]



Kommentare zu diesem Beitrag